on
Bringing AI power to Ethereum with Accessible zkML
We at TACEO are thrilled to finally announce our as-of-yet largest project in the zkSpace in cooperation with =nil; foundation – a pipeline for proving ML models to L1.
Why does the industry need provable ML
There's no question that ML is coming into the realm of decentralized applications to accelerate ecosystem growth. More and more use cases need to rely on the power of Machine Learning in making well-calculated decisions over a massive amount of data, based on a large set of parameters. But for applications to use ML securely, we need ML models to be provable - for example, provable to Ethereum within a smart-contract.
Just as we tend to reduce trust to any transaction, for a more secured web3, we’d want to implement trustless ML use: namely, prove ML operations execution and the underlying training datasets with zkProofs. And from there, developers will be able to build more secure trustless applications that include ML-based operations, be it in the sphere of DeFi, healthcare, or any other.
Lowering the technical entry point for zk app developers
There are a variety of great projects out there that try to link between the ZK world and Machine Learning (ML). What we mean by linking those two worlds, is to prove the correct execution of an (existing) Neural Network (NN) to some entity (most likely Ethereum). Although other projects are able to prove the building blocks of NNs, and therefore theoretically the network as a whole, it remains impractical to rebuild an NN from scratch inside a circuit, up to almost impossible, when looking at GPT-like models.
Additionally, you still need a background in ZK technology if you want to build even a tiny NN circuit, automatically excluding many ML developers. And without the technology to automate circuit compilation, even with relevant skills present, manual circuit building would take a significant amount of your team’s time.
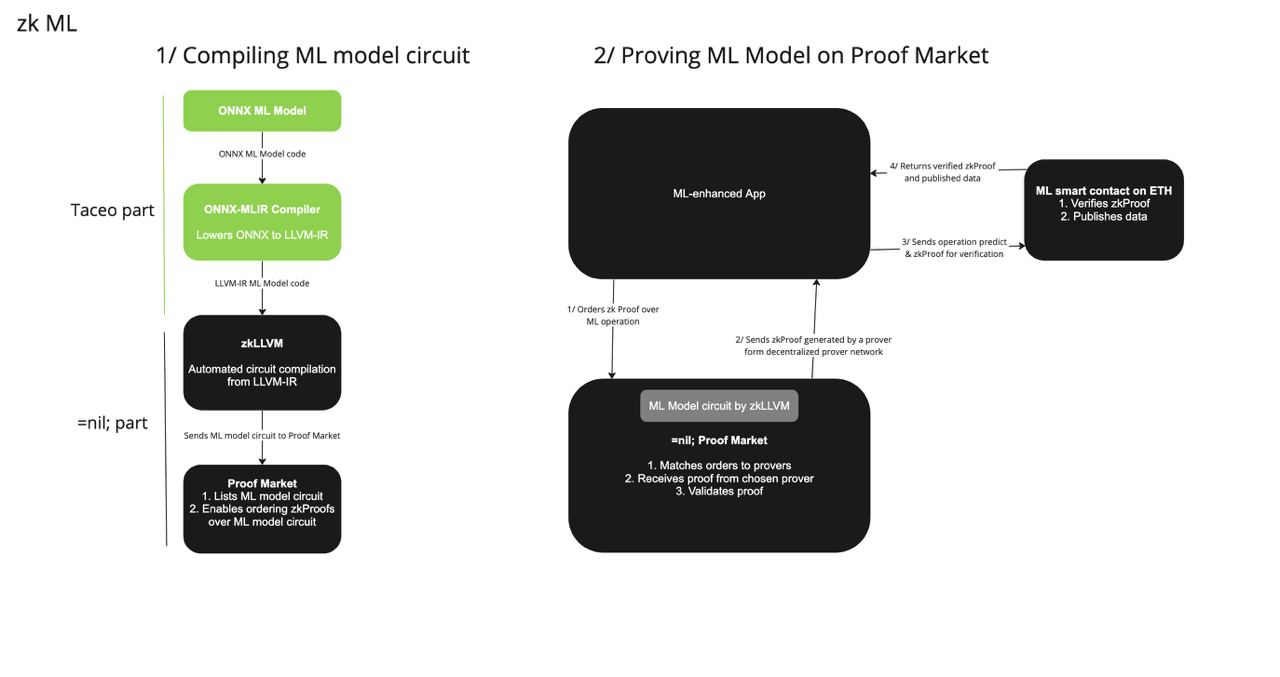
This project aims to enable the composability of ML models with provable computations. On the one hand, we at TACEO plan to leverage the LLVM compiler toolchain to produce circuits from pre-trained, existing NN, eliminating the need to rewrite models inside a SNARK (or your preferred general-purpose ZKP).
On the other hand, the =nil; team is focused on achieving efficient, accessible, and automated circuit compilation from mainstream language input (C++/Rust) through zkLLVM using the Placeholder proof system.
This blog post aims to give a high-level description of the project without getting too technical. Please note that the project is now in the development stage.
Imagine you are an ML developer involved in a DeFi lending protocol. You create this excellent NN to deduce the protocol's parameters in real time. Of course, you want the lending protocol's user's trust. Therefore, you open-source the network with all the intricacies for everyone to see. Even though everyone agrees on the NN's awesomeness, pundits still claim that they do not trust that the protocol uses those derived parameters and not from a secret NN, favoring certain parties.
You, of course, want to convince even the most paranoid people, and therefore, you prove the correct execution of your NN with a ZKP. But how do you do this without a crypto background? Do you have to write the NN again with all attributes and parameters in a zkDSL? Most likely, you do not know what a zkDSL is anyway...
=nil;’s zkLLVM Circuit Compiler
They say innovation occurs in the intersection of disciplines, and of course, if we want to get Machine Learning into the Zero-Knowledge world, we have to start with… Compiler Construction!
But let's go back a few steps – in contrast to many other projects, =nil; plans to solve circuit engineering with zkLLVM, a tweaked version of LLVM. The idea is to build on the existing LLVM toolchain to obtain a circuit compiler.
From a (very) high-level view, one of the advantages of this approach is that there is no need to design/maintain a zkDSL (domain-specific language). In an ideal future world, you do not have to be a cryptographer to write zk circuits. Nevertheless, when going down the path of zkDSLs, "normal" developers must at least study the zkDSL and rewrite existing programs in that DSL, taking up much of their resources and introducing more potential sources of bugs.
This contrasts zkLLVM, where developers can use their favorite LLVM frontend language (C/C++, Rust) to write programs that get transformed into circuits, enabling a broader field of developers into the zkSpace.
To summarize, zkLLVM is an LLVM-based circuit compiler capable of proving computations in whatever mainstream development languages LLVM supports: C++, Rust, JavaScript/TypeScript, and other languages. Considering that the circuit is just another form of a program, zkLLVM directly transforms the code into a different representation. There are obviously more details to this part, and if you're interested in digging into zkLLVM topic, here's a detailed blog post on that.
I skipped a lot (really a lot) of intricacies with this explanation, but as I said, we do not want to get too technical.
Large Models (GPT-2) and zkLLVM compatibility
Allowing more people to write zkApps - applications enhanced with privacy-preserving features using ZKPs – will hopefully lead to new and exciting products and ideas. Nevertheless, sometimes, writing your apps from scratch in a zkDSL or an LLVM frontend is not feasible, e.g., imagine you have to rewrite a (large) neural network in any zkDSL out there. Also, for that matter, the overhead of naively rewriting the model for zkLLVM in any supported frontend is simply too much.
For the sake of an example, suppose someone wants to prove a GPT-like model. Something like GPT-2 or BERT. Those networks have millions of attributes and operations. Nobody wants to write that in C/C++/Rust (or zkDSLs). But we have one advantage when using the zkLLVM pipeline. We have a common lowering point! This means if we can lower existing models to LLVM-IR (and therefore zkLLVM), there is no need to create GPT-2 from scratch in a zk-friendly programming language.
The tricky part now is: how do we create the neural network's circuit? Remember, the premise is you seriously don't want to write the neural network in C/C++ or Rust from scratch. So, how do we do that?
Even More Compiler Construction: ONNX-MLIR Framework
You thought this post was about crypto, it is in fact, about compilers!
As I said, you want to avoid writing your neural network in any LLVM frontend. Luckily, we can follow the steps of zkLLVM and use another great tool from the LLVM project, namely MLIR. (And no, the ML in MLIR does not stand for Machine Learning, but rather Multi-Language Intermediate Representation).
MLIR is an extensible compiler infrastructure that allows the creation of domain-specific compilers, among many other use cases. To keep it short (again), there are two primary components when working with MLIR:
- Dialects are a logical grouping of operations under a common namespace.
- Passes are applied during compilation on an IR to transform/optimize it or lower it to another IR.
From a domain-specific frontend (think: some language/DSL), MLIR allows computing passes on the DSL for optimization and lower to a target IR - with sometimes many lowerings to different dialects in-between. MLIR also defines an “LLVM” dialect, which is (basically) LLVM-IR. One such domain-specific compiler is ONNX-MLIR.
ONNX (Open Neural Network Exchange, this is the last new acronym, we promise) is an open standard allowing a common exchange and file format of trained neural networks.
With that out of the way, ONNX-MLIR is a compiler written with the MLIR compiler framework that can lower ONNX models to LLVM-IR. And if we can lower it to LLVM-IR, we can use zkLLVM!
At least when we are done with our project.
To summarize, starting with a neural network in ONNX format, like GPT-2, we will use a tweaked version of ONNX-MLIR to apply the already defined optimization and lowering passes of ONNX-MLIR. But instead of producing LLVM-IR, we will lower it to zkLLVM, which will allow us to compile circuits directly from ONNX! ML developers then can build circuits from their existing models without any cryptographic background. You can simply take existing models in ONNX format and compile circuits from them, irrelevant about attributes and operations. Of course, circuit compilation is just the first step for proving large GPT-like models. A single prover would need substantial computational power to prove GPT-2, but this is not the focus of our project.
Although not our scope, =nil;’s team is constantly improving their proof system Placeholder. One substantial progress for the proof system is distributed proof generation, where several proof producers can unite to compute a single proof. With this, each prover could do the job with cost compared to the Mina state verification!
Further research
We have outlined the target compilation chain above, but there is still much research and engineering work to get us there.
In the first months of the project, we will (and are already) investigate open questions concerning the efficiency of the compiled models, design efficient components that can be used as a kind of accelerator in the zkML prover for different operations, decide how to best emulate floating-point arithmetic in the proof system and how the various components in the pipeline can best be integrated.
Once we are certain that we have identified the best way forward it will be time to put the above research into practice and build the ONNX frontend for the zkLLVM pipeline. Expect some first results in Q4 2023.