on
How to choose your ZK-friendly hash function?
In our last blog post we investigated the usefulness of hash functions for zero-knowledge use cases. Thereby, we stumbled upon many ZK-friendly designs, each with advantages, disadvantages, and optimizations for different performance metrics. With MiMC1, GMiMC2, Poseidon3, Poseidon24, Rescue5, Griffin6, Anemoi7, Neptune8, Grendel9, Reinforced Concrete10, Tip511, and Monolith12 one can quickly lose track of which hash function is the most efficient one in which scenario. In other words: How the heck do I choose the hash function for my use case?
As is always the case, the answer is not straightforward and depends on various factors, such as the used ZK proof system and the primary cost metric for the use case. For the lazy, we prepared two decision trees to help you choose. Scroll to the end of the page to find them!
I only care about a fast prover
In the first scenario, we investigate the best hash function just considering prover performance, i.e., minimizing the cost inside the ZK circuit. Researchers have come a long way since first trying to minimize the number of multiplications with MiMC. We again point to our last blog post, where we explained the design principle of low-degree equivalence. These designs are especially well suited for minimizing prover cost and their main distinguishing feature is using both $ y= x^d $ and $y=x^{1/d} $, which leads to a secure hash function with a small number of rounds (and thus also a small number of constraints). In contrast, the expensive $ y=x^{1/d} $ computation is as cheap as $ y= x^d $ inside the ZK circuit due to the equivalent representation $ y=x^{1/d} \equiv x = y^d $.
The first hash function successfully using this design approach was Rescue5, which later got slightly optimized as Rescue-Prime. However, researchers soon realized it could be further optimized and introduced the Griffin6 and Anemoi7 hash functions.
In their works, the authors of Griffin and Anemoi compare their hash functions for performance when used in various configurations and proof systems. Concretely, they show huge advantage when used in R1CS-based zero-knowledge proof systems (e.g., 96 constraints for Griffin vs. 240 constraints for Poseidon), as well as for AIR-based STARKs and Plonk proof systems when using the original Plonk-gate (173 gates for Griffin vs. 518 gates for Poseidon).
So what to choose now? Griffin and Anemoi provide very similar performance metrics inside various ZK-proof systems. There are configurations where Griffin is slightly better and some configurations where Anemoi has a slight edge. However, Griffin requires less $ y=x^{1/d} $ computations which makes it faster to evaluate on modern CPUs (see, e.g., benchmarks here). This faster hashing performance can be significant for precomputing Merkle trees outside the ZK circuits. It can also contribute to faster ZK proving in the phase where traces must be filled. Consequently, our choice falls on Griffin.
Hashing outside the proof system is equally important
Unfortunately, what makes Griffin/Anemoi/Rescue so fast inside the ZK circuit makes them comparatively slow for native hashing. The $ y=x^{1/d} $ computations are significantly slower on CPUs compared to, e.g., the low-degree $ y=x^d $ computations. Consequently, for use cases where native performance is equally important to ZK prover performance, one should refrain from choosing Griffin or Anemoi. For example, these use cases include recursive STARKs, where one has to compute a huge Merkle tree natively at each recursion step while proving in ZK that it was computed correctly. As shown in, e.g., Fractal13, using a hash function with slow native performance can result in the prover spending most of its time building Merkle trees.
So, what is the best hash function for fast plain performance? Well, as always, that depends. This time the main question one has to answer is: "Does my ZK proof system support lookup arguments?"
If the answer to this question is a yes, then you are in luck. You can (probably) use one of the hash functions designed around native performance using lookups, such as Reinforced Concrete10, Tip511, and most recently Monolith12.
The next question is: "What is the native prime field of my proof system?"
If you answer with a big $ \approx 256 $ bit prime field, such as BLS12-381 or BN254, then you can use Reinforced Concrete. This hash function was the first to find a way to use the lookup argument on large prime fields, resulting in a significantly faster native hashing performance for large field sizes compared to previous hashes (e.g., $ 3.5\mu s $ vs $ 20.4\mu s $ for Poseidon using BN254).
If the answer is a small prime field, such as the 64-bit Goldilocks field, which was recently used in the FRI-based Plonky214 proof system, or the 31-bit Mersenne prime field, seen in Plonky315. In that case, you can use the Monolith hash function, the fastest ZK-friendly hash function for native hashing to date. Its performance even comes close to the native hashing speed of traditional hash functions, such as SHA3.
Your proof system does not support lookup tables. What now? Don't worry. There are still plenty of designs to choose from. While Poseidon3 has long been regarded as one of the fastest ZK-friendly hashes for native performance, it was recently improved to create Poseidon24, which outperforms Poseidon by ~40% in different settings while keeping the same ZK performance.
So we arrived at either Reinforced Concrete, Monolith, or Poseidon2. However, there is another thing to consider when using Reinforced Concrete. Namely, it uses lookup tables for native hashing performance, which may be susceptible to cache-based side-channel attacks. While there is no attack exploiting them published anywhere in the literature, this might change in the future and should be kept in the back of the mind. If this is already a problem for your use case, consider switching to Poseidon2.
I don't trust all these new hash functions
That is a fair point. Designing new hash functions which are both secure and efficient, is a difficult task. Experience has shown that, despite the best efforts of designers to make their hashes secure, cryptanalysts come up with new and more efficient ways to break the security of new symmetric primitives. Thus, new hash functions should ideally be battle-tested over several years to allow researchers to better understand a given design's security. Then, after years of failing to break the hash function, one can finally start to trust the design. In that sense, Poseidon or Rescue-Prime, which were published in 2019 (4 years ago), or MiMC which is even older, might be the best choice. Due to their age, these are also the hash functions with the most widespread adoption. Thus, attackers had more incentives to break the security of Poseidon, Rescue, and MiMC compared to other ZK-friendly hash functions. Furthermore, they were part of a bounty program with the goal to further understand their security. With that being said, investigating the security and privacy of these hash function is a whole other topic which we might cover in future blog posts.
Ultimately, the best way to get trust in the security of the designs is by going through the years-long journey of standardization. So far, ZK-friendly hashes have yet to be standardized by institutions such as NIST. Also the community-standard developed at zkproof.org does not yet have ZK-friendly hashes on their agenda. However, this might change. With the ever-increasing need for symmetric ciphers and hash functions for zero knowledge, homomorphic encryption, and multiparty computation use cases, NIST is considering starting a standardization process for these designs (see here) and is very interested in hearing about reports of use-cases from industry.
Finally, you can just use NIST-standardized hash functions such as SHA-256, which is a very conservative choice. Almost all popular proof system implementations provide custom made circuits for SHA-256, and while they are still much less efficient than hash function designs that are optimized for ZK use-cases, they can be a valid trade-off point if you want to be as conservative as possible or have external constraints.
These hash functions are not provable secure, give me something else
If you do not trust any newer cryptographic hash function at all (for whatever reason), there is still a design for you! Hash functions based on the hardness assumptions typically found in digital signatures, such as the discrete logarithm problem, exist as well and have also been implemented in some ZK frameworks, such as Halo216. Most notably, the Pedersen17 hash, and its lookup-friendly successor Sinsemilla18, have been proposed for ZK applications. While these typically have slower native and prover performance compared to cryptographic hash functions, only provide collision resistance (for fixed size inputs) and no full pre-image resistance, and are not considered post-quantum secure, they come with a security proof reducing their security to the discrete logarithm hardness assumption. This, however, makes them only viable options for proof systems using large $ \approx 256 $ bit prime fields, in which discrete-log is actually considered to be hard.
Decision Trees
As promised, here are two decision trees to help you choose. We weighted the first one w.r.t. the use case.
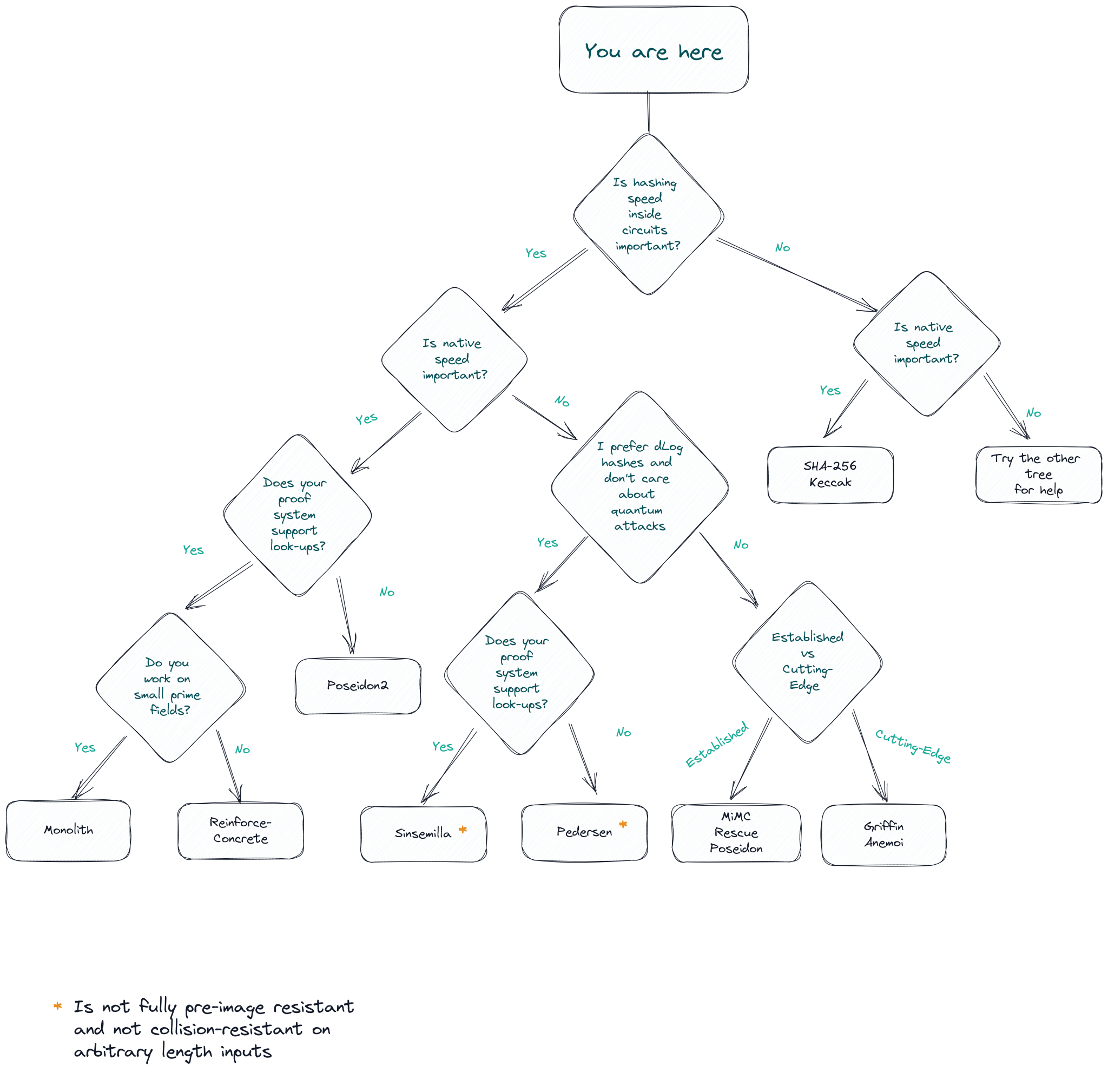
The second one helps you choose regarding trust assumptions and novelty of the hash!
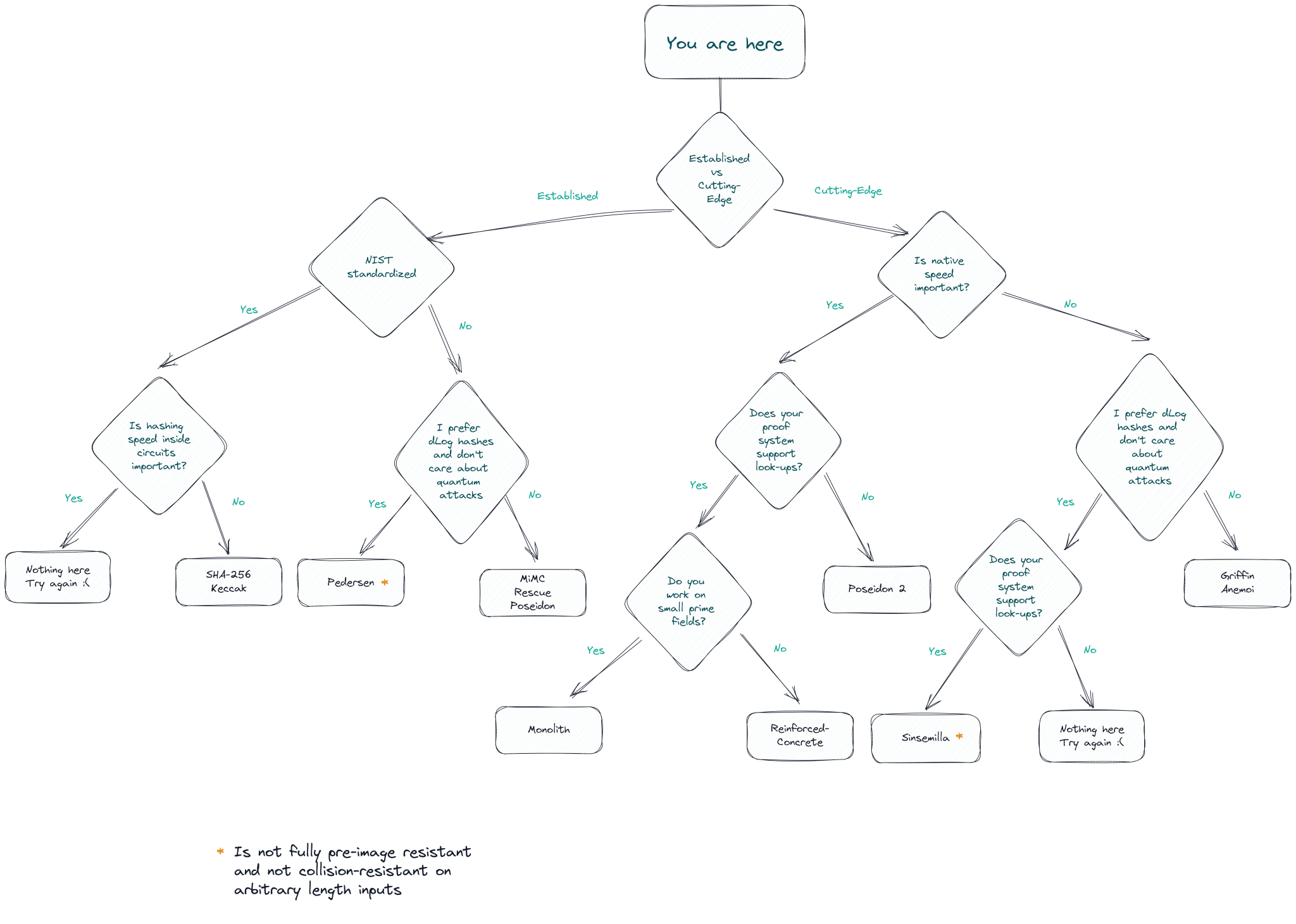
Conclusion
So, choosing the proper hash function for your ZK use case can be difficult, but we broke it down by asking some basic questions. Is prover performance the only thing you care about? Use Griffin6. Is plain performance equally important? Use Reinforced Concrete10 for large prime fields with lookup arguments, Monolith12 for small fields with lookup arguments, and Poseidon24 otherwise. Do you care mostly about already established designs with decent arguments for security? Use Poseidon3 or Rescue-Prime5, depending on whether your performance metric includes native hashing. We hope that with this post, we helped you navigate the ever-expanding field of ZK-friendly hash functions, and you can choose the right one for your use case.
Disclaimer: The author of this blog post is a co-designer of Griffin6, Reinforced Concrete10, and Monolith12. Our company, TACEO, has close ties to the IAIK institute of Graz University of Technology, which (including alumni) is involved in the design of 8 out of 12 symmetric hash functions named in this and the previous blog post, and our cofounders were involved in designing 6 of these hash functions, including Poseidon3.
Poseidon: https://eprint.iacr.org/2019/458
Poseidon2: https://eprint.iacr.org/2023/323
Neptune: https://eprint.iacr.org/2021/1695
Rescue: https://eprint.iacr.org/2019/426
Anemoi: https://eprint.iacr.org/2022/840
Griffin: https://eprint.iacr.org/2022/403
Grendel: https://eprint.iacr.org/2021/984
Reinforced Concrete: https://eprint.iacr.org/2021/1038
Monolith: https://eprint.iacr.org/2023/1025
Sinsemilla: https://zcash.github.io/halo2/design/gadgets/sinsemilla.html
Fractal: https://eprint.iacr.org/2019/1076
Plonky3: https://github.com/Plonky3/Plonky3