on
MPC's Role in Advancing World ID Privacy Features
In this post, we aim to illustrate the capabilities of secure multiparty computation (MPC) through a specific example. In recent months, our collaboration with the Worldcoin team has focused on assessing the potential of leveraging MPC to introduce decentralization into a specific aspect of their ecosystem, namely the World ID. Let's start by learning a bit about the specific components of their protocols that require decentralization and then delve into the details of how MPC can be applied to solve the identified problem. Finally, we will share some performance benchmarks from both a CPU and GPU version of the protocol. If you really want to get to the nitty-gritty details, we point you to our research paper. We also want to encourage you to have a look at the blog post by Worldcoin to read about the project from their perspective.
A World ID TLDR
Before we jump into the technical parts of the post, we need some clarifications. If you're not already familiar with Worldcoin, here's a quick TLDR. Feel free to skip this section if you're familiar with World ID and the proof of personhood.
At the core of Worldcoin's ecosystem lies the World ID — a digital identity securely linked to an individual through cryptographic means. The basis of the World ID is a proof of personhood, which, in a nutshell, is "a mechanism that establishes an individual’s humanness and uniqueness"1. To obtain a World ID, a user has to register by biometric identification at a dedicated Orb. The World ID enables users to authenticate themselves as distinct individuals to various platforms, which becomes even more important during the rise of AI.
To prevent users from registering multiple times, Worldcoin utilizes iris scans conducted by the orb operators. Upon completion, users receive a World ID, enabling authentication on their platform. Importantly, subsequent verification processes occur with privacy preservation through zero-knowledge proofs and don't involve the iris scan again. The only instance where an iris scan is relevant is during the initial sign-up, preventing individuals from registering multiple times. This is done by comparing the iris scan to a database of already registered users. We will deep-dive into this process in the next section!
If you are interested in learning more about Worldcoin, we recommend checking out their whitepaper. They also have a nice blog.
Decentralizing the Database
So, how can MPC enhance the decentralization of World ID? To grasp the current challenges faced by Worldcoin, we turn to the insightful blog by Matthew Green. In his privacy-focused analysis of the Worldcoin protocol, he highlights a crucial point: despite the absence of direct links between the existing iris codes database and personal information, a large collection of real-world iris codes could still pose inherent value and risks.
Originally, the Worldcoin database was centrally hosted by the Worldcoin Foundation. However, in their ongoing efforts to promote decentralization within the ecosystem, Worldcoin has funded research through community grants to explore various privacy-enhancing technologies.
One area of focus was transitioning the uniqueness check to MPC. This approach would allow the database to be split across multiple parties, none of whom would have access to the actual Iris Codes. Through MPC, it's still possible to check if a code exists in the decentralized database, but the holders wouldn’t learn the contents of the database or the queried code—greatly enhancing the system's privacy.
With our team's deep background in MPC research, we were especially drawn to this challenge and grateful for the opportunity to work on this important problem through the Worldcoin grant.
MPC Primer
This section serves as an introduction to MPC for those not familiar with the technology. Feel free to skip if you are already acquainted with it.
We start with the textbook description: MPC is a subfield of cryptography that enables multiple parties to jointly compute a function $f$ over their combined inputs while keeping these inputs private.
OK, let's dissect that information. Similar to ZK, the evaluated function $f$ is usually represented as an arithmetic circuit. The inputs to $f$ are secret-shared2 among the parties. Every party evaluates the circuit locally on their shares and communicates with the other participants when necessary. After the parties finish their computation, they reconstruct the result of the function $f$ without ever telling anyone the secret inputs. In practice, the parties computing the function are not necessarily the same parties that provided the inputs.
The literature defines several security settings for MPC, which describe how the different parties are allowed to behave without breaking security. For this blog post, it is sufficient to know the following:
- Semi-honest security: In this setting, parties are assumed to adhere to the protocol specification but are allowed to attempt to gather more information about the other parties' inputs. This is also referred to as passive security.
- Malicious security: In this setting, parties are permitted to deviate from the protocol specification, send incorrect values, or even drop out when it benefits them. Maliciously secure MPC protocols detect this behavior, either aborting the execution or trying to continue on while excluding the malicious parties from the remainder of the protocol. This is also known as active security.
- Honest majority: In this setting, it is assumed that more than half of the parties are honest. This is a common assumption in MPC protocols as it allows for highly efficient protocols.
Looking ahead, after discussing our MPC-based solution, we shortly compare it to a solution based on homomorphic encryption and argue why MPC can achieve stronger security with the same set of trust assumptions, while also being more efficient.
The uniqueness check protocol
OK, back to the topic at hand! If you're interested in a detailed discussion of the uniqueness check, we recommend reading this comprehensive explanation of why and how it works. The referenced article looks into the mathematics behind the iris scan's uniqueness and its rationale. However, understanding the math isn't a prerequisite for comprehending the rest of the blog post, as we'll provide all the relevant information.
Let's have a quick look at the pseudocode of the Iris Code matching protocol (imagine this being a python-like language):
def is_iris_in_db(query, db):
result = false
for item in db:
combined_mask = query.mask & item.mask
difference = (query.code ^ item.code) & combined_mask
distance = difference.count_set_bits()
if distance < combined_mask.count_set_bits() * threshold:
result = true
break
return result
Listing 1: a pseudo-code implementation of the Iris Code matching protocol.
So, what's happening here? The db represents the already registered iris
codes, and query is the iris scan of the user currently in registration. Each
query comprises two parts: a mask and the actual code. The mask is crucial
for filtering specific aspects of the scan, such as in cases where an eyelash
covers parts of the eyes. code is a bit vector of length 12,800, representing
the iris scan. All registered scans store their respective mask captured during
the iris scan.
At the beginning of the check, the protocol combines the two masks to filter the
relevant sections of the scans. Following that, the protocol XORs the two bit
vectors to determine their distance with respect to the previously combined
mask. Counting all set bits after the XOR operation yields the Hamming distance.
If the distance falls short of a pre-defined threshold, the protocol terminates and
yields true. If no such distance is found, we return false.
Jumping ahead in time, we make the following assumption which is crucial to the concrete efficiency of the protocol execution in MPC. We assume an honest majority of parties: For example, with 3 total parties, only 1 is allowed to be adversarial. MPC protocols for such scenarios can have much more performant protocols for certain operations, allowing us to be multiple orders of magnitude more efficient than using MPC protocols for dishonest majorities.
To MPC-ify the protocol, we need to modify the pseudocode above:
def is_iris_in_db(query, db):
result = false
for item in db:
combined_mask = query.mask & item.mask
difference = (query.code ^ item.code) & combined_mask
distance = difference.count_set_bits()
result = result || (distance < combined_mask.count_set_bits() * threshold)
return result
Listing 2: The Iris Code matching protocol suitable for MPC.
This time we can't stop the search right when we find a match, or else we leak information from the database.
To work around this, we gather all the comparison results, accumulate them together, and then return the final outcome.
Remember that in this case the inputs to the function query and db are secret-shared among the parties.
Main Operations
Let us break down the protocol into bite-sized pieces and investigate each one in a bit more detail. As a reminder for each item in the shared database, we want to:
- calculate the Hamming distance to the queried Iris Code (based on their combined masks),
- compare the Hamming distance to a threshold (based on the combined mask),
- aggregate the results of the comparison into the final result.
Have a look at the following picture:
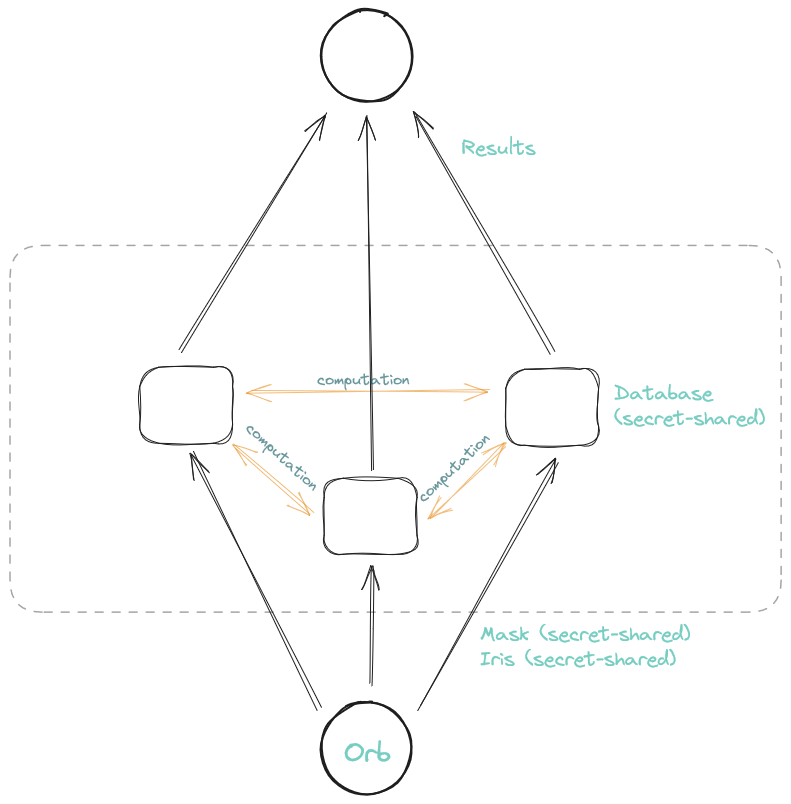
Figure 1: The MPC architecture of the uniqueness check protocol with exemplary three computing nodes
The picture illustrates the complete flow of the MPC uniqueness check protocol. Beginning at the orb, the user scans their iris, which is locally secret-shared and transmitted to the computing nodes along with the also secret-shared mask. The computing nodes conduct the lookup in the secret-shared database without accessing the plain Iris Code or the database itself. Each computing node sends its local share of the result to the sign-up sequencer, which aggregates the results and issues the cryptographic material.
So, let's have a look at the necessary steps in detail.
Hamming distance
The first operation is the calculation of the Hamming distance. In plain, we could XOR the two Iris Codes together, then count the number of bits that are set in the result. The main issue when translating this into the multiparty setting is that the result of the calculation is a larger datatype (i.e., for our assumed Iris Code size of 12,800, we need at least 14 bits to represent the result of the Hamming distance calculation). In most popular MPC protocols, linear operations can be done without communication between the parties, so XOR is a cheap operation. However, counting the results is a nonlinear operation: a trivial strategy is to use 6400 half adders to add two bits together (each of those requires 1 AND gate), then use 3200 two-bit adders to add those results together, continuing this process (an addition tree) until we arrive at the final result. (As a side note, this process can be optimized a bit since the original inputs are bits, so we know that after one level the 2-bit result values can only be in $[0,1,2]$, but not $3$.)

This simple addition strategy results in about $25,000$ AND gates for the calculation of the Hamming distance. Even ignoring the relatively high depth of the addition tree, which can present problems in high-latency connections, repeating this process for a database of 1 million elements would result in a per-party communication of over 3 GB.
Efficient dot products for Hamming distance
Many MPC protocols assuming an honest majority of parties have a way to efficiently calculate a dot product of two vectors $\langle a, b \rangle = \sum_i a_ib_i$. By efficient, we here mean that the communication required for the calculation of the dot product is not dependent on the size of the vectors at all.
We can use this efficient dot product protocol to efficiently calculate the Hamming distance of two vectors. We first assume that the individual bits of the Iris Codes are transformed from binary shares over $\mathbb{F}_2$ to shares over a larger ring $\mathbb{Z}_{2^k}$, where $k$ is large enough to fit the aggregated result. For the class of MPC protocols we are considering in this article, we have relatively efficient conversion protocols, and while the conversion process still scales with the size of the Iris Code, this step could be performed once for the secret-shared database of Iris Codes and then later reused for many potential Iris Code queries.
Assuming we now have two vectors $a,b$ of secret shared Iris Codes with values of ${0,1} \in \mathbb{Z}_{2^k}$ we can now calculate the Hamming distance as follows: $\mathsf{hd}(a,b) = \sum_i a_i - 2\langle a, b\rangle + \sum_i b_i,$ instead of $\mathsf{hd}(a,b) = (a \oplus b)$.count_set_bits(). The two sums can be computed locally by the parties without any communication, while the dot product can be calculated efficiently via the efficient protocols mentioned above. Finally the multiplication by the constant 2 and the subtraction/addition of the 3 results can also be performed without any interaction, bringing the total communication for the Hamming distance calculation down from $25,000$ bits to just $k$, where $k$ is at least $14$ (we use $k =16$ in our experiments since it plays nice with native datatypes in programming languages). This is a massive improvement of over $1000\times$, making this a very competitive approach.
Including the mask
The keen reader might have observed, that in the previous section, we ignored the mask in the hamming distance calculation. In other words, we computed $\mathsf{hd}(a,b) = (a \oplus b)$.count_set_bits() instead of $\mathsf{hd}(a,b) = ((a \oplus b) \wedge m)$.count_set_bits() where $m$ is the combined mask. While trivially including the mask in the calculation requires a multiplication per bit in the Iris Code throwing away our gains in communication, we came up with a different solution: When encoding the iris bits as masked bits with 0 when the mask is not set, -1 when the mask and the iris bit are set and 1 otherwise, the whole threshold comparison gets simplified to $\langle a, b\rangle > (1-2 \cdot \text{threshold}) \cdot m.$count_set_bits().
For more details on why this checks out please have a look at our research paper. The point for this blog post is that with this optimization we keep our communication improvements, while also reducing the workload for the hamming distance calculation. We further note that $m.$count_set_bits() can also be calculated as a dot-product of the two individual masks when they are encoded as ${0,1} \in \mathbb{Z}_{2^k}$. Thus, in the final protocol, we first compute two dot products in MPC which we then have to compare (also in MPC).
Threshold Check
After the calculation of the Hamming distance, we need to compare it to some threshold value to check if the Iris Code is a match or not. With the optimization from the previous section, we basically need to compute $c > t \cdot m$ where $c$ and $m$ are shared elements in $\mathbb{Z}_{2^{16}}$, and $t$ is some threshold represented as real number. Embedding real numbers into MPC protocols usually leads to some performance penalties which is why we choose to approximate $t=\frac{a}{b}$ by some 16-bit numbers $a$ and $b$. We chose 16-bit because this approximation gives enough accuracy and 16-bit again fits nicely into CPU registers. Thus, we can rewrite the comparison to $a \cdot m - b \cdot c < 0$. To calculate the left-hand side of the operation we first have to lift the sharings of $c$ and $m$ in $\mathbb{Z}_{2^{16}}$ to sharings in $\mathbb{Z}_{2^{32}}$ to prevent the multiplications from overflowing. This lifting step is not trivial in MPC and requires communication, but it has acceptable performance for our use case. We refer the interested reader again to the research paper for more details on this step.
So now to the comparison of $r < 0$ where $r$ is shared in $\mathbb{Z}_{2^{32}}$. Remember that we used a slightly larger ring $k=16$ than needed ($k=14$) above? This ensures that the subtraction we performed above thus not produce a "wraparound" in the ring, and the most significant bit is set only if the value is negative. Thus we just have to extract the most significant bit of $r$ to perform the comparison. Luckily, this is a common and useful sub-operation in MPC protocols, so there already exist a lot of protocols to achieve this.
A basic idea is to convert the arithmetic share over $\mathbb{Z}_{2^k}$ to a vector of bit-shares $b_1, b_2, \dots b_k$, and then return the share $b_k$. However, since we do not need the other bit shares, a bit of computation and communication can be saved in this conversion protocol. The main work in the conversion protocol is essentially the execution of 2 addition circuits, where one can choose tradeoffs depending on the type of addition circuit used. A packed Kogge-Stone adder has depth logarithmic in the number of bits to be added but has 2 times the minimum required number of AND gates. A standard depth-wise full adder chain meets the minimum number of bits but has depth linear in the number of bits to be added. Depending on the use case and environment, both setups can be the better choice.
Aggregation of Results
The previous two sub-operations can be independently applied to all items in the database, which also means a good potential for parallelization. However, once the result of the comparison is computed, we need to aggregate the individual comparison results into a final result.
This boils down to a logical OR with a fan-in of the size $N$ of the database. As a side note, if we would be sure that there is only ever a single or no match in the database, the aggregation can be done using XORs, which can be performed locally. However, this is another assumption and while the parametrization of the Iris Code algorithm should prevent this from happening, there is no guarantee that a query is never matched by two or more items.
Therefore we just perform the aggregation in a binary tree with $N$ leaves and the nodes being OR gates. This requires N-1 OR gates (which require 1 AND gate internally each) and can be done in depth $\log N$. Since we are working with single-bit shares at this point, the communication complexity of this step is $N-1$ bits in $\log N$ rounds. Finally, the parties communicate to reveal the aggregated result to the output party.
Further optimization
While the description of our protocol so far already included some highly technical details, our actual implementation uses more optimizations, such as combining multiple different MPC protocols (ABY3 and Shamir secret sharing), optimizing Shamir secret sharing with so-called Galois rings, and many more. Describing these, however, would definitely be out of scope for this blog post which is why we again want to advertise our research paper.
Malicious Security
In the previous section, we talked about "honest majority" MPC protocols, and their simplest, most efficient instantiations only achieve semi-honest security. While in the finally deployed protocol, we are staying in this model, in the beginning of the project we also investigated "malicious security" which allows parties to deviate from the protocol specification. For educational purposes, we will discuss some aspects of this security setting in this section.
Several different approaches exist to upgrade a semi-honest protocol to a protocol with malicious security, with a few popular approaches including:
- Verifying the multiplications in the protocol via "triple sacrificing".
- Verifying the integrity of the computation via information-theoretic message authentication codes (MACs) that are computed alongside the shares.
- Parties proving they followed the protocol specification via zero-knowledge proofs.
In our experiments (see the report), we investigated the approaches to malicious security from Fantastic Four, Swift, and Motion-FD, which include all of the above variants. In general, malicious security adds a bit of overhead to the computation and communication. In particular, the probability of catching a misbehaving party using methods based on triple sacrificing and information-theoretic MACs usually depends on the size of the triples/MACs used. As an example, to achieve 40-bit security (i.e., a misbehaving party is not found only once in 1 trillion protocol runs) for multiplication of two 16-bit ring elements using our targeted protocols, we would need to use MACs that are represented as 56-bit ring elements (and usually the 16-bit ring elements also need to be embedded in 56-bit ring elements as well). For our use cases this can mean an about 8x increase in communication (we now need to communicate 2 elements, the share, and its MAC, and they are about 4x larger). If we think about bit shares, there the overhead is even larger, since we start with 1-bit elements, which now need to be embedded into 41-bit elements to achieve the 40-bit security.
However, for protocols mainly dealing with bit shares, different methods of achieving malicious security exist, such as generating bit multiplication triples via cut-and-choose and then sacrificing them to prove the validity of the actual multiplications. In protocols using mixed representations, such as the Iris Code matching discussed in this article, there is even merit to combining different techniques, such as using MACs for larger ring elements, and sacrificing bit triples for securing bit operations. However, in doing so, great care has to be taken at the points where the used mechanisms are changed.
Experiments
OK, that was a lot of technical detail! Let's take a step back and look at some results. We implemented the full MPC version of the iris matching protocol and ran some benchmarks.
Let's first start with the result of a 3-party MPC protocol, where each party only consists of one core with one thread on the same machine. Thus, the parties are connected with localhost networking. For this benchmark, we have a database with 100,000 Iris Codes:
| Runtime (ms) | Data (MB) | Throughput (M el/s) | |
|---|---|---|---|
| 2x Dots | 130.61 | 0.4 | 0.76 |
| Threshold | 14.47 | 2.138 | 6.91 |
| Or-tree | 0.87 | 0.012 | 114.94 |
| Total | 145.94 | 2.55 | 0.69 |
Table 1: Runtime and communication for the single-threaded CPU iris matching protocol.
To summarize, to match a new iris with a database of 100,000 irises, the protocol takes only 146 ms (single-threaded), while the network communication is very small with just 2.55 MB. That is a throughput of ~690 thousand Iris Code comparisons per second. While these results are already impressive, for deployment we can optimize them even further using graphic cards!
GPU implementation
Our final protocol consists of several steps with different performance characteristics: The dot product is computationally expensive, while only one communication round is required, whereas the threshold comparison (and the final aggregation) has many communication rounds with comparably little computations in between. People who are into graphic cards might now think: dot products are a prime use case for GPU acceleration. And they are right. This is the reason why we investigated the performance gains when implementing the whole protocol on GPUs. The second part, however, with the many communication rounds is usually regarded as slow since in straightforward implementations data has to be moved between CPUs and GPUs for every round, which induces high delays.
Luckily though, with Nvidia NCCL, we can instruct the GPUs to directly access network interfaces, so no CPU-GPU data transfer is ever required in our implementation. So we ended up creating an MPC protocol implementation where GPUs of different computing parties were talking to each other directly. Pretty cool if you ask us!
And the performance is also something to be seen. For the following benchmark, we consider a real-world scenario close to what will actually be deployed: First, during sign-up both eyes of a single person are queried against the database. Second, each eye is rotated 31 times to strengthen the accuracy of the matching protocol. Thus, the query of a single person consists of 62 Iris Codes. Third, the database will be queried in batches and a batch consists of 32 people, or a total of 1984 Iris Codes, which will get matched against a database of 4.2 million Codes. Furthermore, the 64 eyes (2 eyes of 32 people) in the batch are, in addition to matching with the database, also matched with each other to ensure uniqueness in the batch as well. Our benchmarks also include this intra-batch matching. When executing the protocol with 3 AWS P5 instances, where each party has access to 8 H100 GPUs and the parties are connected by a network with (theoretically) 3.2 Tbps, we get the following performance numbers:
| Runtime (ms) | Throughput (G el/s) | |
|---|---|---|
| 2x Dots | 370.57 | 22.46 |
| Threshold | 1569.23 | 5.30 |
| Total | 1939.80 | 4.29 |
Table 2: Runtime and throughput for the GPU iris matching protocol.
These performance numbers are something to be seen! They improve the throughput from 690 thousand Iris Code comparisons to an astonishing 4.29 billion comparisons per second. Wow. With this setup, the protocol is definitely fast enough for real-world deployment.
Source Code
If you want to dive deep into the source code of the project you are in luck, all implementations are public and can be found here. This repository went through several cycles of auditing and contains CPU and GPU implementations, as well as the additional code required for deployment.
Comparison to Homomorphic Encryption
Another commonly used privacy-enhancing technology is homomorphic encryption (HE). HE enables the server to directly compute functions on encrypted data, and can also be seen as a 2-party specialization of MPC. Let's briefly investigate the setup, security guarantees, and performance of applying HE to the distributed database check use case.
First, the setup of HE is actually quite similar to MPC: Since the main goal of the protocol is to hide the database of Iris Codes, a computing party only has access to an encrypted version of this database. Crucially, this party must be oblivious to the decryption key to preserve the privacy of said database and therefore, there must be another party owning this decryption key. The workflow of the database check protocol would be the following: First, the Orb uses a public key to homomorphically encrypt a new Iris Code and sends the ciphertext to the computing party that has access to the encrypted database. This party can then compute the whole protocol on the ciphertexts to produce an encryption of the result bit, which indicates whether there was a match in the database. Finally, this encrypted bit needs to be sent to the party knowing the decryption key to get the result in plain.
Security, Trust Assumptions, and Performance of HE
Comparing the security guarantees of HE to our MPC solution, one can first observe that in both cases a non-collusion assumption is required. In HE, if the key holder sends the decryption key to the database holder, privacy is lost. Similarly, if the MPC parties combine their shares of the database, they get all Iris Codes in clear and privacy is lost as well. Furthermore, since one can not check whether the HE database holder actually computes the correct protocol, applying HE only results in a system with semi-honest security, similar to the semi-honest variant of our MPC solution. Crucially though, no efficient solution is currently known for extending HE to a maliciously secure setting.
Furthermore, HE is known to add a huge computational overhead to any use case. Looking at benchmarks of the popular ZAMA HE library, where a homomorphic 16-bit integer addition already requires ~60 ms on CPUs (~17 ms on GPUs), one can see that our MPC variant leads to a significantly faster solution since the computational overhead for basic operation is much lower than for HE.
Another thing that is often overlooked when using HE is ciphertext expansion. In other words, encrypting values using an HE scheme results in huge ciphertexts. Using the default parameters in the ZAMA tfhe.rs library for encrypting bits, one encrypted bit requires ~2800 bytes. Consequently, sending 12800 encrypted bits (i.e., one Iris Code) from the Orb to the computing parties would require sending ~37 MB which is already more communication than required by our MPC solution for a database size of 100k entries. Finally, the encrypted database of 100k codes would require about 3.5 TB of storage space, meaning it is infeasible to keep the database in RAM.
Conclusions
To wrap things up, we want to highlight that Worldcoin is currently in the process of deploying the GPU variant of our protocol in their World ID infrastructure. With more than 6 million people already signed up for World ID, this project is one of the biggest MPC use cases ever to be deployed.
Looking back, the journey from first talks with Worldcoin, via protocol design, first implementations, GPU implementation, to now deployment took pretty much exactly one year. Since our background is mostly academia we were not part of large-scale deployments before. Thus, this journey was especially exciting for us, showing us the differences between academic prototypes and actually deployed protocols. The insights we learned will definitely be valuable in our journey ahead.
From a technical perspective, other lessons can be learned from this project as well. First, it is a prime example of MPC, when applied with care and strong hardware, being already fast enough for real-world applications with data from millions of users. Second, since one can instruct GPUs to directly access network interfaces, MPC protocols can definitely benefit from using them as well. Thus, if you consider deploying other MPC protocols, you can probably gain some speedups by using GPUs.
For now, you can expect to hear more from us on collaborative SNARKs in the future. Nonetheless, we are excited to continue our collaboration with Worldcoin and are looking forward to keeping you posted with all updates on this exciting project!
See, e.g., Pragmatic MPC, section 2.2