on
The MPCSQL Hackathon Project

Performing queries on secret-shared databases - sounds like a dream? My goal was to turn that dream into reality during the first internal annual hackathon at TACEO. My name is Roman and I'm a cryptographic engineer at TACEO. Let's start with an introduction on what secret shared databases are and what queries we can perform on them.
What is a Secret Shared Database?
A "traditional" relational database (DB) stores plaintext data in a structured way and allows us to shape data via tables, datatypes, relations and more. Most importantly, we can formulate Structured Query Language (SQL) queries on our DB to retrieve and transform data to gain valuable insights on our precious digital oil. Because data is valuable, problems quickly arise if we want others to gain some insights from our DB, but perhaps not learn anything. Suppose that multiple mutually distrusting entities (let's call them Alice and Bob) would like to perform analysis on their combined datasets to learn more about the bigger picture of their data of common context. This would only be possible by disclosing the full datasets to one party who could then run the analysis queries on. Surely technology has advanced enough and we can do better.
Secret Shared Databases use Multiparty Computation (MPC) to split information into secret shares, where the whole DB is built on that principle from bottom up. This allows Alice and Bob to split their datasets into secret shares where an MPC network can collaboratively compute queries on their combined datasets. Once the network is finished computing the result, there are various options to open the secret shared result to learn the cleartext of the computed result. Of course, Alice and Bob need to agree an a query beforehand and they should be willing to disclose the result of the query.
Why would anybody be willing to disclose the result of a query? Because a query, if well defined, only reveals not-so-sensitive parts of datasets, such as "How many retired people live in London and New York?" (this could translate to SELECT COUNT(*) FROM people WHERE status='retired'). Imagine this query is run on the shared databases of the social insurance institutions of the UK and the US, where really a lot of personal, sensitive information is kept secret.
How are we going to build such a fancy DB system?
For simplicity we'll start with a simple datatype, unsigned 64-bit integers, or short: u64. Ultimately, every piece of data just consists of bits or bytes, so we can build more sophisticated datatypes on top of that later (spoiler: one week of hackathon wasn't enough to move beyond u64 ... 🙂). That means, every column will use the u64 datatype.
To constrain the topic even further, we'll focus on the MPC part of queries only, this project won't focus on parsing SQL into any form of AST, this is something that 0xThemis will love to take care about in case we move forward with secret shared databases. 😉
Before the hackathon went live we had the opportunity to get some consultancy from our experienced colleagues in regards to scoping our projects and identifying relevant resources. My supervisors threw this paper at me that focuses on private set intersections and fast database joins on secret shared data. The protocol described in that paper uses the ABY3 protocol which we'll use in this project. Having that information, we can start to define a table structure!
Table Structure
A table consists of a list of rows where each row consists of a list of column values. Additionally, a table also has a list of column labels so that our columns have actual names, as we know it from databases. TACEO is well known to have fallen in love with Rust 🦀 (as you might have guessed from the u64 type), so this project's code snippets will be crabby.
To start off, here is the definition of the ClearTable and ClearRow which hold plaintext data.
use mpc_core::protocols::rep3_ring::ring::int_ring::IntRing2k;
use mpc_core::protocols::rep3_ring::ring::ring_impl::RingElement;
use mpc_core::protocols::rep3_ring::Rep3RingShare;
pub struct ClearTable<T: IntRing2k> {
pub name: String,
pub rows: Vec<ClearRow<T>>,
pub column_labels: Vec<String>,
}
pub struct ClearRow<T: IntRing2k> {
pub col_vals: Vec<RingElement<T>>,
}
Bear with me, this is a hackathon, I dare to skip the fact that each row and column_labels must be of the same length. Spoiler: No mental invariants were violated throughout this hackathon. Phew ... Also note that we are helping ourselves here using TACEO's mpc_core crate that takes care of fundamental networking and ABY3 stuff for us. Rep3 stands for "replicated three party" secret sharing and uses ABY3 under the hood - as required by the paper that we are building upon!
Now that we've defined "clear tables" we also need to define "secret shared tables", or just "Tables" and "Rows":
pub struct Table<T: IntRing2k> {
pub name: String,
pub rows: Vec<Row<T>>,
pub rows_mask: Vec<Rep3RingShare<T>>,
pub column_labels: Vec<String>,
}
pub struct Row<T: IntRing2k> {
pub col_vals: Vec<Rep3RingShare<T>>,
}
We built some conversion utils that turns clear tables into tables and opens tables into clear tables. Additionally, we also implemented loading/storing (clear) tables from/to csv files which allows us to easily test our functionality later on. You might have spotted the rows_mask field on the struct Table which leads us to the next topic - defining queries!
Before we move on: This will be all of the persistence that we'll do for the "database" part - you may call it "in-memory DB" if you wish. But still, we have persistence using csv files.
First queries
SQL consists of many operations that can be perfectly chained one after another, let's think about WHERE statements first (and we need no scientific paper for this yet!): When restricting the result set of a query using WHERE statements, we apply constraints to every row of the table one by one. A row either fulfills the constraint, or it doesn't. This leads us to introducing an additional column to our Table - the row mask! The row mask either holds the value 1 or 0 depending on whether the row is present (1) or not (0). Don't worry, the row mask is secret shared, so we do not know if a row is present during MPC.
How do we compute the row mask for a given row? We use TACEO's mpc_core crate that provides many common operations in MPC, such as comparing two secret shared values, or comparing secret shared values to public values. Of course, further operations like multiplication, exponentiation, and bitwise operations are also provided by the mpc_core, but we don't need them now.
The row mask helps us to perform other operations later, such as aggregating results (e.g. SUM(some_column), COUNT(*)) or opening tables. For example, SELECT SUM(col_a) FROM my_table WHERE col_b=11 works by performing the WHERE filter first that computes the rows_mask, followed by the aggregation of SUM(col_a) that computes the sum for each row in MPC as
\begin{equation} \texttt{SUM(col\_a)} = \sum _{i=0}^{\texttt{rows.len()}-1} \texttt{rows\_mask} _i \cdot \texttt{rows} _{i, j} \end{equation}
where $j$ is the index (or column number) of col_a.
For opening tables, we can follow the principle of opening the row mask first and if the row mask is 1 we move forward with opening the row itself, whereas we skip opening the row contents in case the mask is 0.
When thinking about table operations (WHERE statements, selecting a subset of columns, joins, group by, ..) we notice that every (intermediate) operation produces a table again. That's no surprise though as this is just how SQL works, but this is still very descent as we can use our table struct for inputs, intermediate values and final results!
Let's take a look on how performing queries looks like in Rust. Before we start with queries
you might want to check how easy it is to setup the networking configuration for the three MPC nodes.
The following code snippet shows the start of the main function for each MPC Node. Note that all three nodes run the same code, the behavioral difference is introduced through the network config file which specifies which party ID (0, 1, or 2) the current program executes. The network config also lists connection information for the other two nodes and their IDs.
Example network config files can be found in the TaceoLabs/co-snarks repository.
use mpc_core::protocols::rep3::network::{IoContext, Rep3MpcNet} // using mpc_core 0.6.0, see TaceoLabs/co-snarks
use mpc_net::config::{NetworkConfig, NetworkConfigFile}; // using mpc_net 0.2.0, see TaceoLabs/co-snarks
// [..]
rustls::crypto::aws_lc_rs::default_provider()
.install_default()
.map_err(|_| eyre!("Could not install default rustls crypto provider"))?;
let config: NetworkConfigFile =
toml::from_str(&std::fs::read_to_string(&args.config_path).context("opening config file")?)
.context("parsing config file")?;
let config = NetworkConfig::try_from(config).context("converting network config")?;
let mpc_net = Rep3MpcNet::new(config).unwrap();
let mut io_context = IoContext::init(mpc_net).unwrap();
The instance io_context will later assist us in performing MPC computations in regards to sending and receiving data from other parties.
Queries in Rust
We've created a simple query builder that mimics SQL statements of the form SELECT some_col, SUM(other_col) FROM the_table WHERE <predicate>. The following code snippet shows how to load shared tables from csv files from an input directory, perform a query on one of the tables, and store the query result as a clear table to the output directory.
use mpcsql::{persist, table, query}; // some logic that we omit in this blog post
// [..]
let tables = persist::get_shared_tables(&args.in_dir, config.my_id);
let query: query::Query<u64, Rep3MpcNet> = query::Query::builder()
.table("cars".to_string())
.select(vec![query::Selector {
column: "num_seats".to_string(),
agg_type: query::AggType::Sum,
}])
.predicate(query::Predicate {
column: "owner_id".to_string(),
value: RingElement::<u64>::from(215),
operator: query::Operator::EqPub,
})
.build();
let mut query_res = query.run(&tables, &mut io_context);
query_res.name = "aggregate_sum_cars".to_string();
let clear_tab = table::open_table(&query_res, &mut io_context);
persist::store_clear_table(&clear_tab, &args.out_dir, config.my_id);
In case you are looking for the removed snippets marked by // [..]: Check the collapsible box regarding network configuration close above this code block.
Our table cars comprises the following structure and data:
| car_id | num_seats | owner_id |
|---|---|---|
| 0 | 4 | 215 |
| 1 | 5 | 215 |
| 2 | 3 | 215 |
| 3 | 2 | 384 |
The query depicted in the above code snippet is equivalent to SELECT SUM(num_seats) FROM cars WHERE owner_id = 215 and produces the following result:
| SUM(num_seats) |
|---|
| 12 |
First Queries: Conclusion
This part so far was quite straightforward. It is actually impressive how simple basic table queries can be formulated in MPC while preserving privacy. The next part is more tricky: Performing join operations on secret shared tables. Stay tuned!
Note that the order of the records in the query result leaks information ..
This is something we did not talk about yet. To properly reveal the results we need to randomly permute the rows of the query result before opening the result. Doing this in MPC is not straightforward anymore and we'll use a technique presented in the "fast joins" paper to randomly shuffle a table's rows, which we'll introduce in the next section of this blog post!
Database Joins
Database joins allow us to define a query that uses data from multiple tables. Let's use the cars table from before and let's introduce another table people to our example. The table cars provides a column owner_id which we'll interpret as a foreign key to the table people. The table below shows an example of our table people.
| id | age | social_insurance_nr |
|---|---|---|
| 23 | 6 | 7384210418 |
| 215 | 49 | 4381060875 |
| 384 | 24 | 7316271100 |
We can now perform an inner join on the tables cars and people to combine the information of both tables, for example to learn the owner's age for each car. The SQL query would look like SELECT people.age, cars.car_id, cars.num_seats FROM cars INNER JOIN people ON cars.owner_id = people.id and the result would be:
| cars.car_id | cars.num_seats | people.age |
|---|---|---|
| 0 | 4 | 49 |
| 1 | 5 | 49 |
| 2 | 3 | 49 |
| 3 | 2 | 24 |
For simplicity, we'll focus on inner joins only, but the concept presented in the next section can be extended to left and right joins as well. Furthermore, we restrict ourselves to the scenario that the join keys are unique within both tables, i.e. one person may own one or no car at all. For this we need to ditch our previous records from the table cars as the owner_id is not unique within that table.
Joins on Secret Shared Tables
The "fast joins" paper introduces a technique to join two tables, where the join keys must be unique within both tables, where the join operation happens in MPC and no information is leaked. The paper's authors call this construction the "oblivious switching network". It turns out that this oblivious switching network is comparably complex to understand and implement, so we decided to realize a simplified solution instead where we use the concepts presented in the paper and come up with our own solution. I already spent half of the hackathon on reading the paper, so I wanted to make sure this project doesn't end up as a readathon. 😉
Our simplified Solution
Our solution does not leak any information besides one party learning statistics about the cardinality of the join and the row indices of the joined records in the original tables.
The Join Procedure:
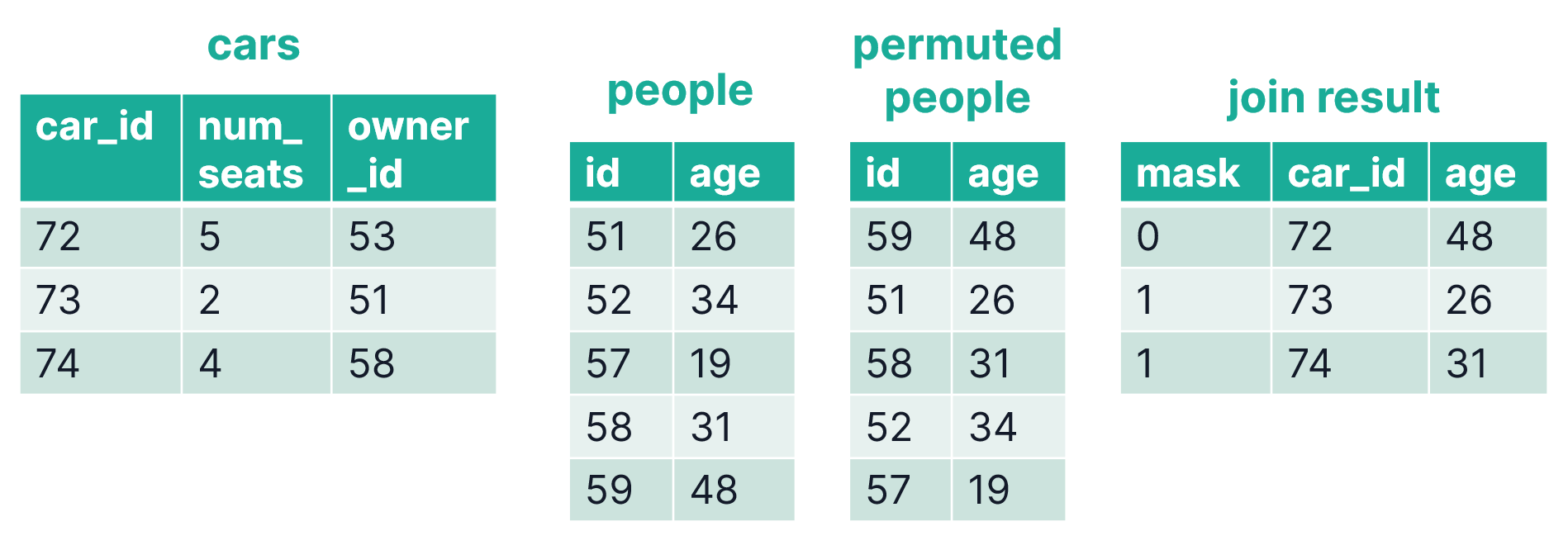
- Let's say we want to join two tables X and Y. Let table X be the table having the smaller row count. In case Y would have less rows than X, we just swap X and Y.
- As the relations between the tables X and Y are bound to be 1:1 at max, we can simply permute Y's rows such that rows having matching join keys end up in the same row number for X and Y.
- We can now compute the row mask according to the join keys. If the join keys match, the row is set to present.
An example based on our cars and people structure:
MPC'ifying the solution
To come up with the desired permutation on Y, we need to perform two operations in MPC:
- Identify matching join keys
- Permute Y such that all but one party do not learn the permutation
We tackle the first point by using randomized encodings on the join keys. For this we use a block cipher, where we know that two plaintexts match in case the ciphertexts match. We perform block cipher encryption in MPC and the encrypted ciphertext is opened to one of the parties. This one party can then create the permutation required to get Y in the correct order.
LowMC has proven itself to be performant in MPC settings. We at TACEO had some LowMC implementation lying around and I ported this implementation to be compatible with the mpc_core crate, so we can use it for this project.
Randomized Encodings
The three MPC parties randomly sample a key for the LowMC block cipher so that no party knows the key in use. This ensures that the plaintext remains confidential, while the ciphertexts can be compared for checking equality of the underlying plaintexts. This approach reminds of bilinear pairings over elliptic curves used in the construction of SNARKs.
Permute Protocol
The second point gets solved by implementing the "permute" protocol presented in the "fast joins" paper. The protocol boils down to one party knowing the actual permutation while the other parties assist with computing the permutation, where the other parties do not learn the permutation itself, which is why this protocol is referred to as the "oblivious permutation protocol".
We'll omit details on the protocol here and refer to Figure 5 on page 13 of the paper for an explanation. All that is left to say here is that we implemented the protocol and provide a "high level" interface to use in the Rust prototype. A part that seemed scary at first was the fact that the permutation protocol uses a two-party protocol internally. It turned out that juggling around with binary shares is quite simple and implementing two-party MPC was easier than expected. The code snippet below shows how to perform an inner join on the two tables from the example above.
use mpcsql::{persist, table}; // some logic that we omit in this blog post
// [..]
let tables = persist::get_shared_tables(&args.in_dir, config.my_id);
let mut joined_table = join::join(&tables, "people", "id", "cars", "owner_id", &mut io_context);
joined_table.name = "people_cars_join".to_string();
let clear_table = table::open_table(&joined_table, &mut io_context);
persist::store_clear_table(&clear_table, &args.out_dir, config.my_id);
The table::open_table function performs a random shuffle of the rows before opening them using the permute protocol. This ensures that no information is leaked based on the ordering of the returned results.
More recent work on Database Joins
The paper we are working with is not the most recent work available. Secret-Shared Joins with Multiplicity from Aggregation Trees allows to have non-unique join keys in both tables while also leaking less information than the "fast joins" paper.
Conclusions
Working on this project was a lot of fun as I built a fresh use case from ground up. A nice take away was that the mpc_core crate is very well suitable to get started with a new project in a short amount of time. It was very surprising to see how easy it is to create basic SQL operations, such as WHERE statements and aggregating results. Implementing joins on the other hand sharpened my mind on how to design logic in MPC. Overall, it was very enjoyable to fully focus on this project and pausing the daily business for one full week - already looking forward to next year's internal hackathon! 🎉
Thank you for following our hackathon series! If you'd like to read more about MPC Core, coSNARKs, or other TACEO tooling, feel free to check out the docs, chat with us in Discord, and follow for news on X!